Face Recognition (31 Celebrities)

Implemented a face recognition classifier which is run across 31 labels (celebrities) with 49 images per label.
Dataset
A Face Dataset of different celebrities after applying MTCNN (Multi-Task Cascaded Convolutional Neural Network) for face detection.
Contains 49 images per celeb with labels that are included are as follows:
1. Akshay Kumar
2. Alexandra Daddario
3. Alia Bhatt
4. Amitabh Bachchan
5. Andy Samberg
6. Anushka Sharma
7. Billie Eilish
8. Brad Pitt
9. Camila Cabello
10. Charlize Theron
11. Claire Holt
12. Courtney Cox
13. Dwayne Johnson
14. Elizabeth Olsen
15. Ellen Degeneres
16. Henry Cavill
17. Hrithik Roshan
18. Hugh Jackman
19. Jessica Alba
20. Kashyap
21. Lisa Kudrow
22. Margot Robbie
23. Marmik
24. Natalie Portman
25. Priyanka Chopra
26. Robert Downey Jr.
27. Roger Federer
28. Tom Cruise
29. Vijay Deverakonda
30. Virat Kohli
31. Zac Efron
Code
#Import packages and models from glob import glob from PIL import Image from torch.utils.data import Dataset,DataLoader from torchvision.datasets import ImageFolder from tqdm.notebook import tqdm import matplotlib.pyplot as plt import numpy as np import pandas as pd import timm import torch import torch.nn as nn import torch.optim as optim import torchvision.transforms as transforms 🗸 10.4s#Declare CelebsDataSet class class CelebsDataSet(Dataset): def __init__(self,data_dir,transform=None): self.data=ImageFolder(data_dir,transform=transform) def __len__(self): return len(self.data) def __getitem__(self,idx): return self.data[idx] @property def classes(self): return self.data.classes 🗸 0.0sdata_dir='../data/Face recognition/Faces' #original_dataset noc= 31 #Number of classes original_dataset=CelebsDataSet(data_dir) 🗸 0.0slen(original_dataset) #length of the dataset 🗸 0.0s1483
#get any image and its label from the dataset to confirm it is working image,label=original_dataset[5] print(label) image 🗸 0.0s0
#Get a dictionary associating target values with folder names target_to_class={v:k for k,v in ImageFolder(data_dir).class_to_idx.items()} print(target_to_class) 🗸 0.0s{0: 'Akshay Kumar', 1: 'Alexandra Daddario', 2: 'Alia Bhatt', 3: 'Amitabh Bachchan', 4: 'Andy Samberg', 5: 'Anushka Sharma', 6: 'Billie Eilish', 7: 'Brad Pitt', 8: 'Camila Cabello', 9: 'Charlize Theron', 10: 'Claire Holt', 11: 'Courtney Cox', 12: 'Dwayne Johnson', 13: 'Elizabeth Olsen', 14: 'Ellen Degeneres', 15: 'Henry Cavill', 16: 'Hrithik Roshan', 17: 'Hugh Jackman', 18: 'Jessica Alba', 19: 'Kashyap', 20: 'Lisa Kudrow', 21: 'Margot Robbie', 22: 'Marmik', 23: 'Natalie Portman', 24: 'Priyanka Chopra', 25: 'Robert Downey Jr', 26: 'Roger Federer', 27: 'Tom Cruise', 28: 'Vijay Deverakonda', 29: 'Virat Kohli', 30: 'Zac Efron'}
#Making sure that images are always 160x160 transform=transforms.Compose([ transforms.Resize((160,160)), transforms.ToTensor(), ]) 🗸 0.0s#Train-test spliting original_dataset=CelebsDataSet(data_dir,transform) train_size=int(0.6*len(original_dataset)) valid_size=int(0.2*len(original_dataset)) test_size=len(original_dataset)-(train_size+valid_size) train_size+=len(original_dataset)-(train_size+valid_size+test_size) train_dataset, valid_dataset, test_dataset=torch.utils.data.random_split( original_dataset, [train_size, valid_size, test_size] ) #Running it for a random image image,label=train_dataset[100] print(image) print(image.shape) 🗸 0.2stensor([[[0.0510, 0.0549, 0.0549, ..., 0.0824, 0.0863, 0.0706], [0.0549, 0.0549, 0.0549, ..., 0.0863, 0.1020, 0.0902], [0.0392, 0.0431, 0.0431, ..., 0.0667, 0.0824, 0.0824], ..., [0.3765, 0.3529, 0.3216, ..., 0.3686, 0.3373, 0.3137], [0.3333, 0.3294, 0.3176, ..., 0.3529, 0.3216, 0.2980], [0.2745, 0.2784, 0.2863, ..., 0.3412, 0.3059, 0.2902]], [[0.0353, 0.0392, 0.0314, ..., 0.0431, 0.0431, 0.0275], [0.0392, 0.0392, 0.0314, ..., 0.0471, 0.0588, 0.0471], [0.0196, 0.0275, 0.0275, ..., 0.0275, 0.0353, 0.0353], ..., [0.1804, 0.1686, 0.1412, ..., 0.2667, 0.2314, 0.2157], [0.1490, 0.1490, 0.1451, ..., 0.2588, 0.2235, 0.2118], [0.0980, 0.1059, 0.1137, ..., 0.2471, 0.2196, 0.2039]], [[0.0392, 0.0431, 0.0314, ..., 0.0745, 0.0745, 0.0588], [0.0431, 0.0431, 0.0392, ..., 0.0784, 0.0902, 0.0784], [0.0353, 0.0314, 0.0314, ..., 0.0627, 0.0745, 0.0745], ..., [0.0745, 0.0667, 0.0471, ..., 0.1765, 0.1490, 0.1294], [0.0392, 0.0471, 0.0471, ..., 0.1647, 0.1373, 0.1294], [0.0000, 0.0000, 0.0157, ..., 0.1529, 0.1373, 0.1216]]]) torch.Size([3, 160, 160])
#iterate over the dataset using dataloader after batching for faster training dataloader=DataLoader(train_dataset,batch_size=32,shuffle=True) for images,labels in dataloader: break images.shape,labels.shape 🗸 0.0s(torch.Size([32, 3, 160, 160]), torch.Size([32]))

#creating a pytorch model by inheriting from nn module class SimpleFaceClassifier(nn.Module): def __init__(self,num_classes=noc): super(SimpleFaceClassifier,self).__init__() #Here we define all the parts of the model self.base_model=timm.create_model('efficientnet_b0',pretrained=True) self.features=nn.Sequential(*list(self.base_model.children())[:-1]) enet_out_size=self.base_model.classifier.in_features #Make a classifier to resize to our number of classes self.classifier = nn.Sequential( nn.Flatten(), nn.Linear(enet_out_size, num_classes) ) def forward(self,x): #Connect these parts and return the output x = self.features(x) output = self.classifier(x) return output 🗸 0.0s#creating an instance of the classifier class to check model=SimpleFaceClassifier(num_classes=noc) print(str(model)[:500]) 🗸 0.8sSimpleFaceClassifier( (base_model): EfficientNet( (conv_stem): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNormAct2d( 32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True (drop): Identity() (act): SiLU(inplace=True) ) (blocks): Sequential( (0): Sequential( (0): DepthwiseSeparableConv( (conv_dw): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=Fa
#ensuring that model works without any errors example_out=model(images) example_out.shape 🗸 0.7storch.Size([32, 31])
#loss function
criterion=nn.CrossEntropyLoss()
#optimizer
optimizer=optim.Adam(model.parameters(),lr=0.001)
🗸 0.0s#ensuring that the shapes match
criterion(example_out,labels)
print(example_out.shape,labels.shape)
🗸 0.0storch.Size([32, 31]) torch.Size([32])transform=transforms.Compose(
[
transforms.Resize((160,160)),
transforms.ToTensor(),
]
)
#create specific loader for these datasets
train_loader=DataLoader(train_dataset,batch_size=32,shuffle=True)
test_loader=DataLoader(test_dataset,batch_size=32,shuffle=False)
valid_loader=DataLoader(valid_dataset,batch_size=32,shuffle=False)
🗸 0.0s#We define the device for the model to run on:
device=torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
device
🗸 0.0sdevice(type='cuda', index=0)
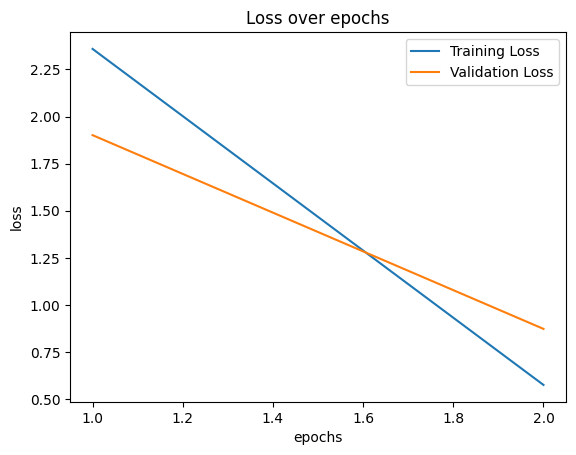
#running through the entire dataset num_epochs=2 #number of times the model goes through the data train_losses,valid_losses,epochs=[],[],[] #lists to catch 'training losses', 'validation losses' and epochs. model=SimpleFaceClassifier(num_classes=noc) #calling the model 'SimpleFaceClassifier' model.to(device) #moving the model to the GPU #Loss function criterion=nn.CrossEntropyLoss() #Optimizer optimizer=optim.Adam(model.parameters(),lr=0.001) #looping through epochs (number of times the model goes through the data) for epoch in range(num_epochs): model.train() #set the model to train running_loss=0.0 #setting a temporary loss variable to '0' #looping through the training dataset loader for images,labels in tqdm(train_loader,desc='Training Loop'): images,labels=images.to(device),labels.to(device) #moving the images and labels to the GPU optimizer.zero_grad() #clear the optimizer gradients outputs=model(images) #catching the outputs after running through the model loss=criterion(outputs,labels) #comparing the output to the labels and #assigning a 'loss' through loss function loss.backward() #compute the gradient according to the loss optimizer.step() #update the optimizer weights accordingly running_loss+=loss.item()*labels.size(0) #increments the 'running loss' by the product of #current loss and the 'batch size' #calculating the training loss by dividing the 'running loss' by the length of 'training dataset' train_loss=running_loss/len(train_loader.dataset) #appending the current 'training loss' to the 'training losses' list train_losses.append(train_loss) model.eval() #set the model to train running_loss=0.0 #setting a temporary loss variable to '0' with torch.no_grad(): #To disable the gradient calculations #looping through the validation dataset loader for images,labels in tqdm(valid_loader,desc='Validation Loop'): images,labels=images.to(device),labels.to(device) #moving the images and labels to the GPU outputs=model(images) #catching the outputs loss=criterion(outputs,labels) #comparing the output to the labels and #assigning a loss through loss function running_loss+=loss.item()*labels.size(0) #increments the 'running loss' by the product #of current 'loss' and the 'batch size' #calculating the validation loss by dividing the 'running loss' by the length of 'validation dataset' valid_loss=running_loss/len(valid_loader.dataset) #appending the current 'validation loss' to the 'validation losses' list valid_losses.append(valid_loss) #appending the current 'epoch' number to the 'epochs' list; epoch+1 because epoch starts from 0 epochs.append(epoch+1) #Print epoch statistics print(f"Epoch {epoch+1}/{num_epochs} - Training Loss: {train_loss}, Validation Loss: {valid_loss}") 🗸 19.4sTraining Loop: 100% 28/28 [00:08<00:00, 3.54it/s] Validation Loop: 100% 10/10 [00:00<00:00, 12.05it/s] Epoch 1/2 - Training Loss: 2.3587397075477146, Validation Loss: 1.901028433361569
Training Loop: 100% 28/28 [00:08<00:00, 3.63it/s] Validation Loop: 100% 10/10 [00:00<00:00, 12.83it/s] Epoch 2/2 - Training Loss: 0.5751913689722227, Validation Loss: 0.872601741069072
plt.plot(epochs,train_losses,label='Training Loss') plt.plot(epochs,valid_losses,label='Validation Loss') plt.xlabel('epochs') plt.ylabel('loss') plt.legend() plt.title('Loss over epochs') plt.show() 🗸 0.1s
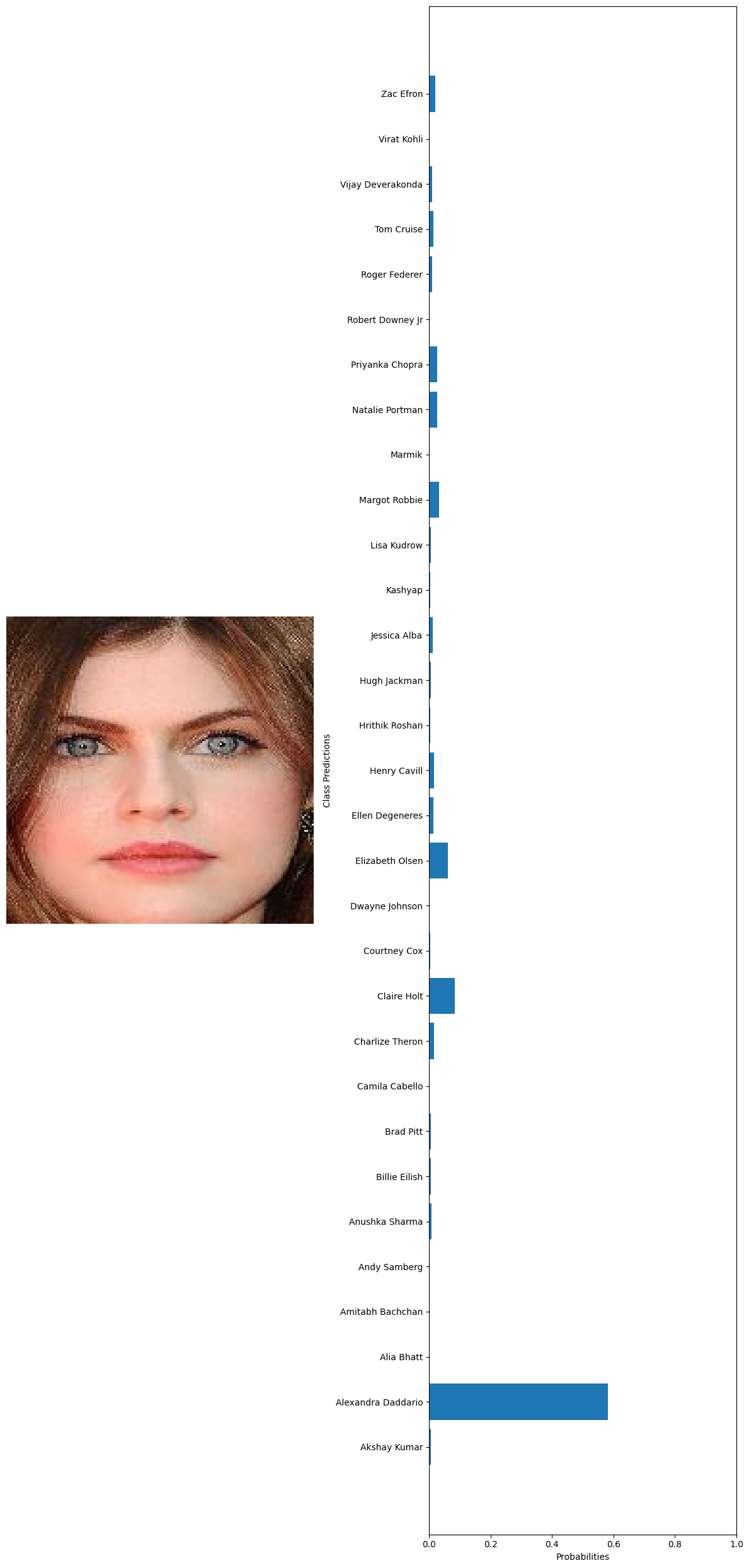
#Load and preprocess the image: def preprocess_image(image_path,transform): image=Image.open(image_path).convert('RGB') return image,transform(image).unsqueeze(0) #Predict using the model: def predict(model, image_tensor,device): model.eval() with torch.no_grad(): image_tensor=image_tensor.to(device) outputs=model(image_tensor) probabilities =torch.nn.functional.softmax(outputs,dim=1) return probabilities.cpu().numpy().flatten() #Visualization def visualize_predictions(original_image,probabilities,class_names): fig,axarr=plt.subplots(1,2,figsize=(12,25)) #Display image axarr[0].imshow(original_image) axarr[0].axis('off') #Display predictions axarr[1].barh(class_names,probabilities) axarr[1].set_xlabel('Probabilities') axarr[1].set_ylabel('Class Predictions') axarr[1].set_xlim(0,1) plt.tight_layout() plt.show() #Example using a hard-coded image test_image='../data/Face recognition/Faces/Alexandra Daddario/Alexandra Daddario_13.jpg' transform=transforms.Compose( [ transforms.Resize((160,160)), transforms.ToTensor() ] ) original_image,image_tensor=preprocess_image(test_image,transform) probabilities=predict(model,image_tensor,device) #getting the class names from the model classifier class_names = train_dataset.dataset.classes visualize_predictions(original_image,probabilities,class_names) 🗸 0.5s
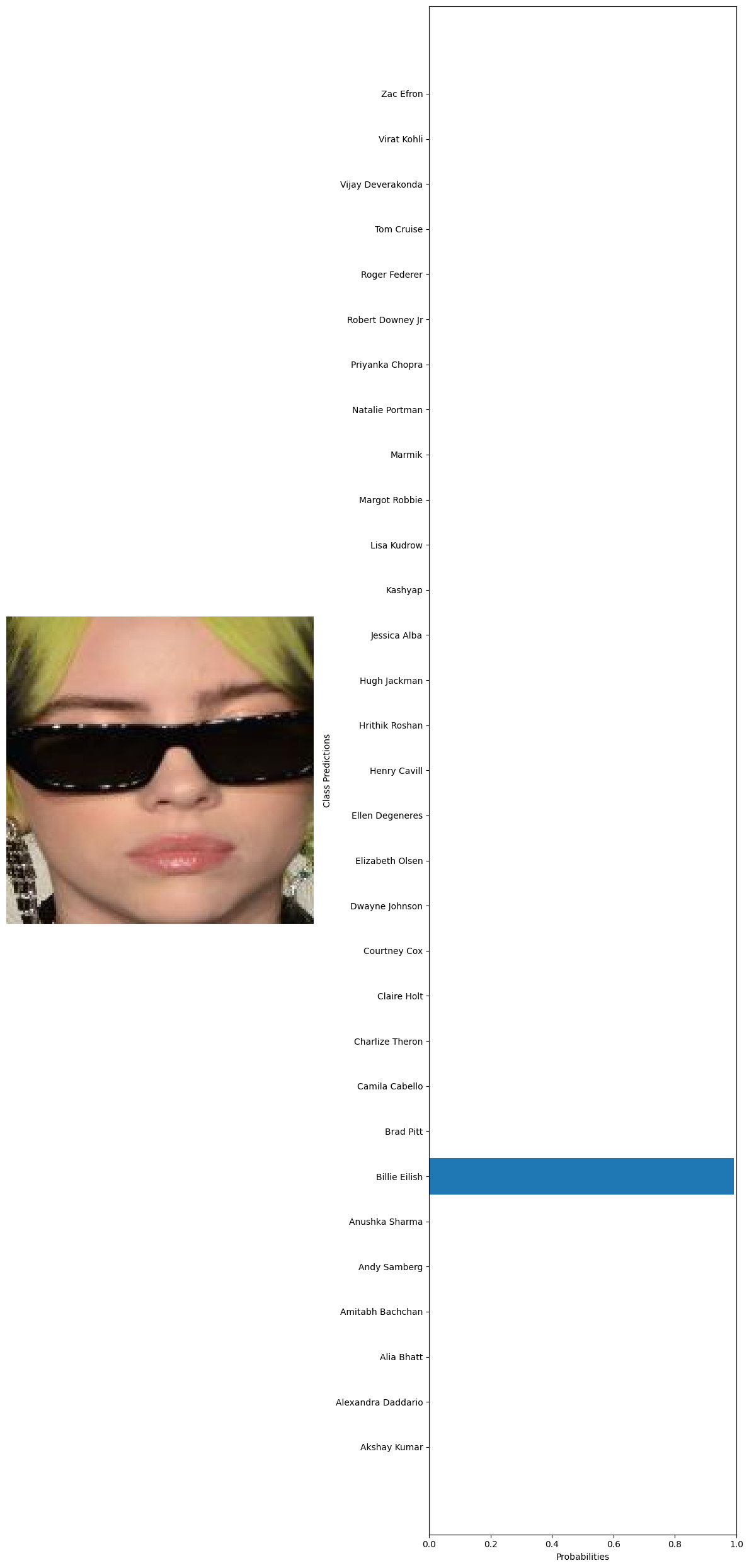
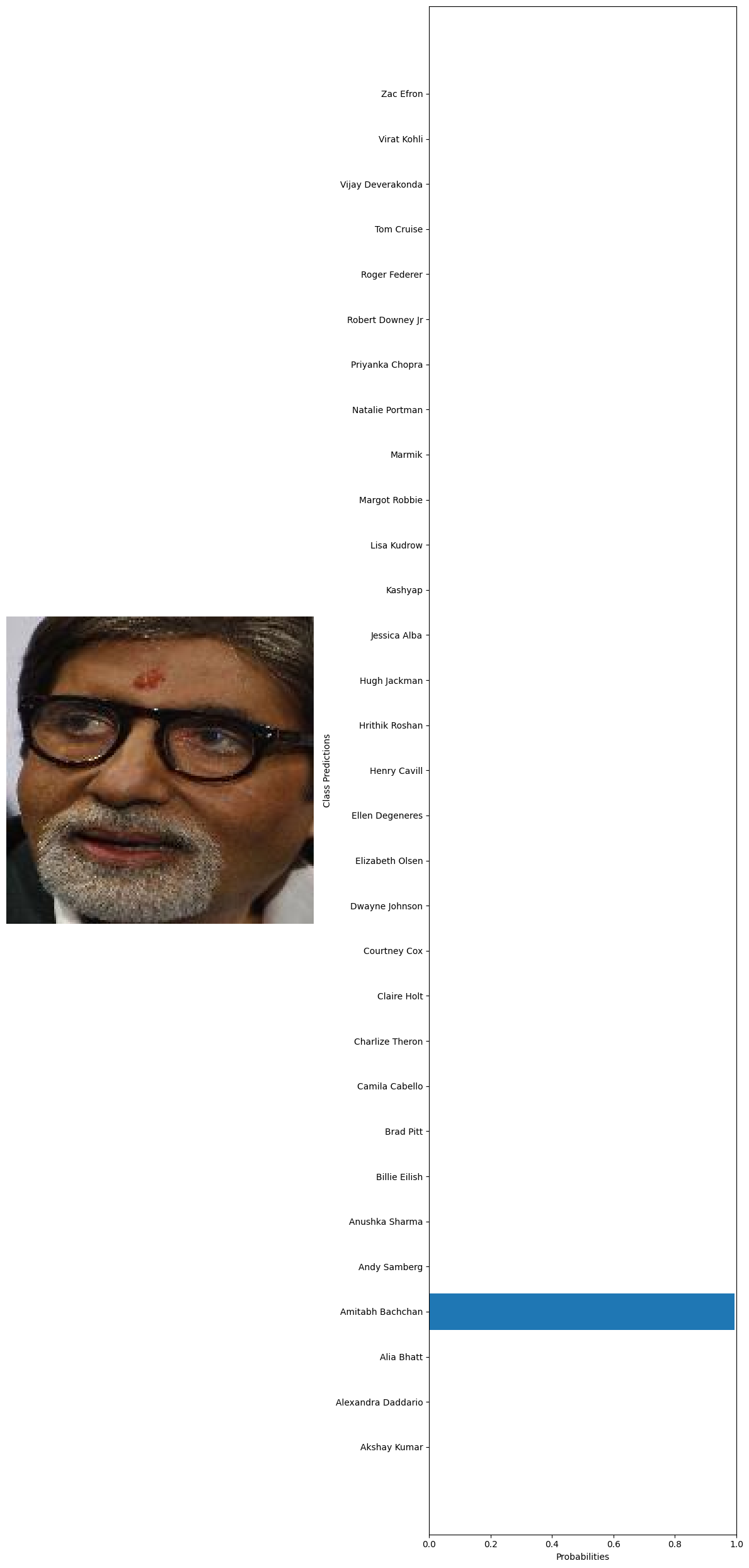
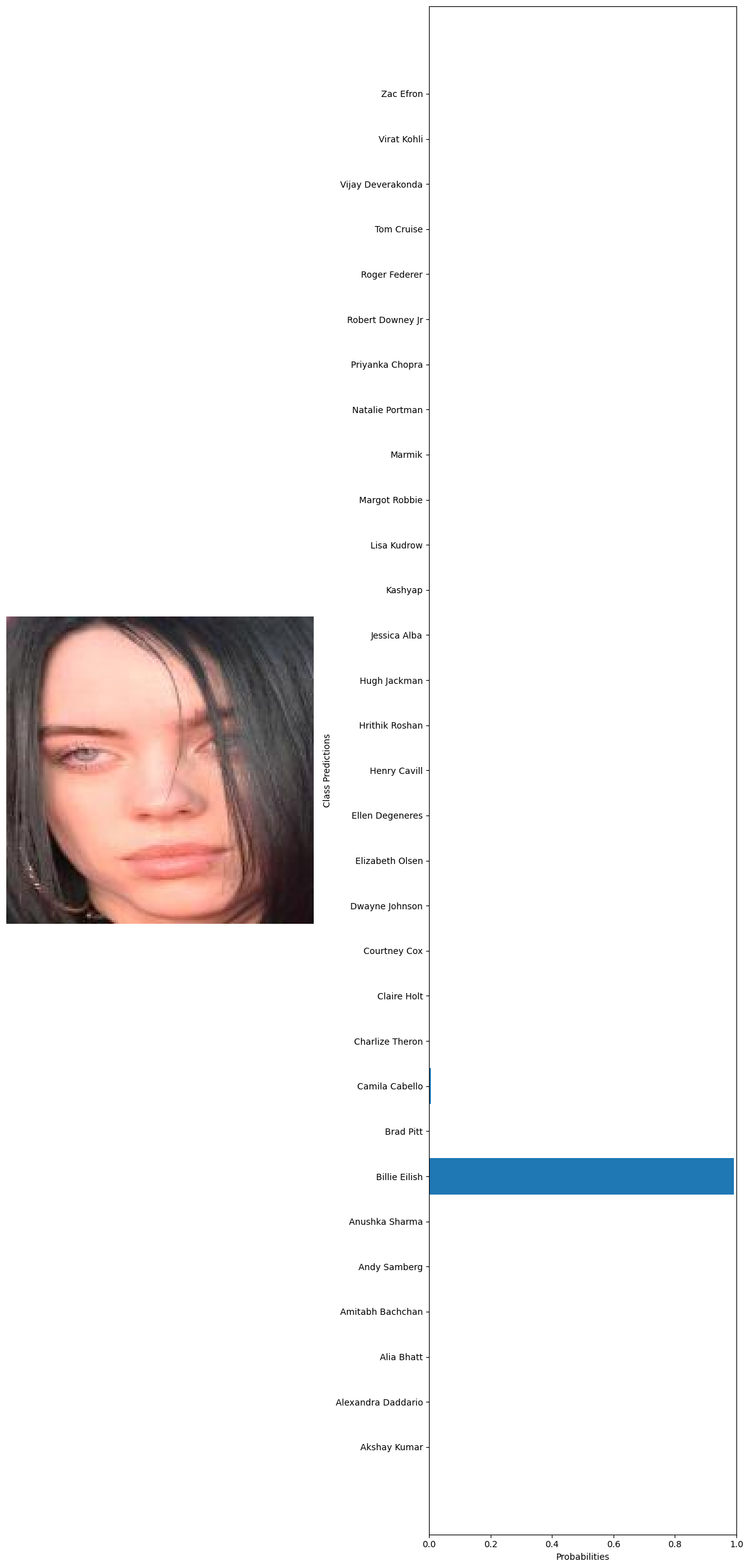
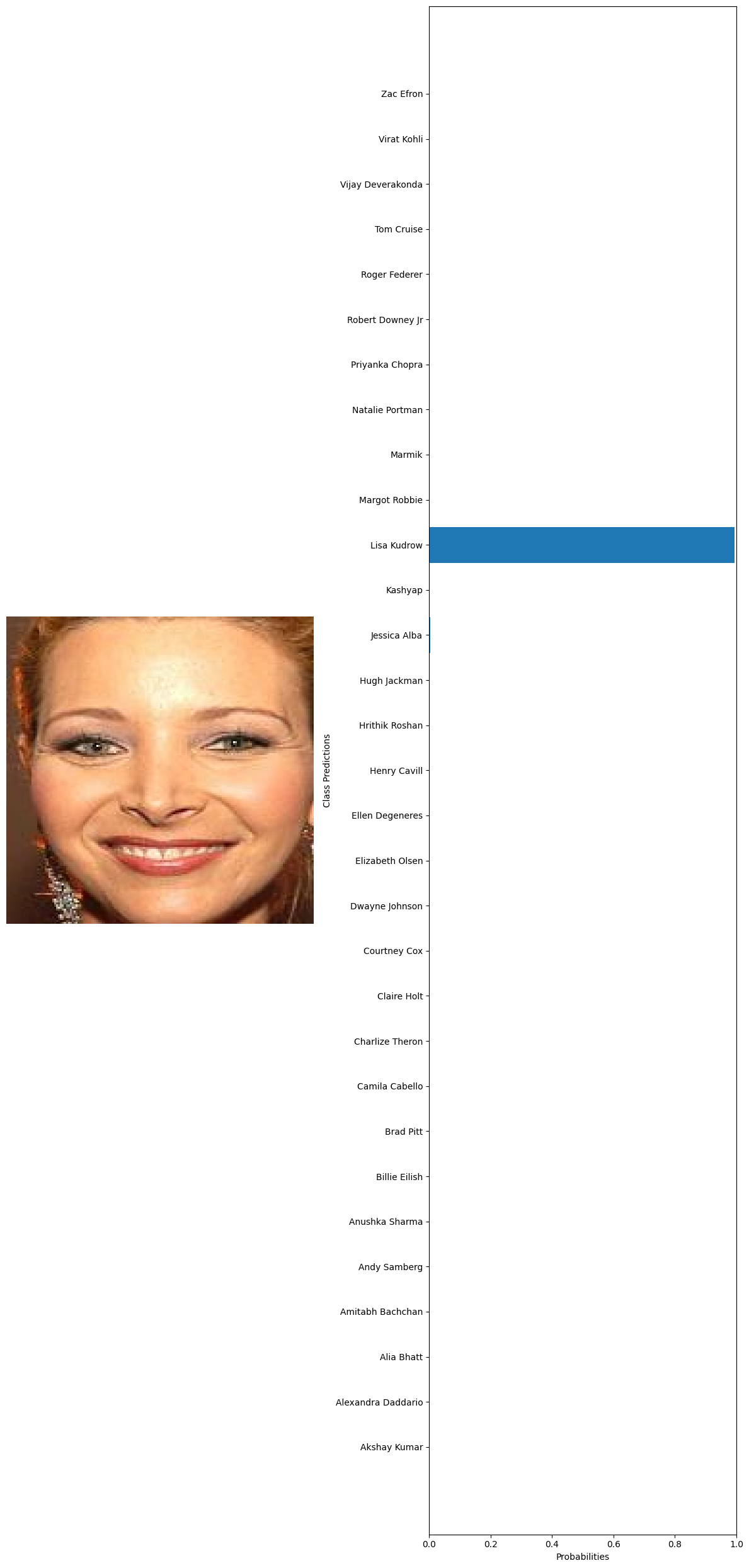
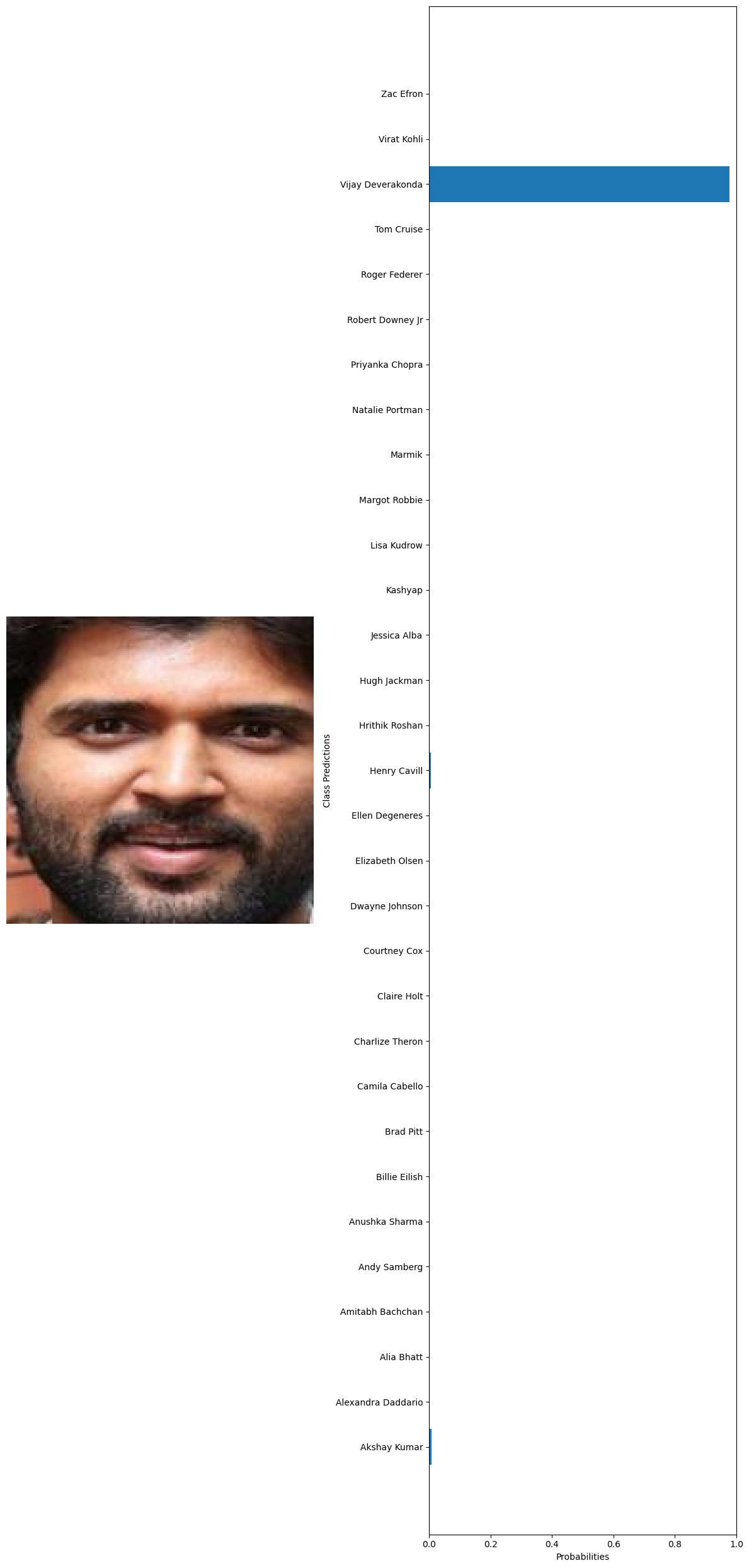
#getting 10 random images from the whole dataset test_images=glob('../data/Face recognition/Faces/*/*') test_examples=np.random.choice(test_images,10) #declaring a variable to calculate the number of current predictions num_correct = 0 #getting the total number of images total_examples = len(test_examples) for example in test_examples: original_image, image_tensor = preprocess_image(example, transform) probabilities = predict(model, image_tensor, device) #getting the class names from the model classifier class_names = train_dataset.dataset.classes #extract true label from file path true_label = example.split('\\')[1] #since class folder name is the label # Get predicted label predicted_label_index = np.argmax(probabilities) predicted_label = class_names[predicted_label_index] # Check if prediction is correct if predicted_label == true_label: num_correct += 1 # Print the true label and the predicted label print("True label:", true_label) print("Predicted label:", predicted_label) visualize_predictions(original_image, probabilities, class_names) #calculating the accuracy accuracy = num_correct / total_examples print("Accuracy:", accuracy) 🗸 4.4sTrue label: Billie Eilish Predicted label: Billie Eilish
True label: Billie Eilish Predicted label: Charlize Theron
True label: Hrithik Roshan Predicted label: Hrithik Roshan
True label: Amitabh Bachchan Predicted label: Amitabh Bachchan
True label: Dwayne Johnson Predicted label: Dwayne Johnson
True label: Claire Holt Predicted label: Claire Holt
True label: Billie Eilish Predicted label: Billie Eilish
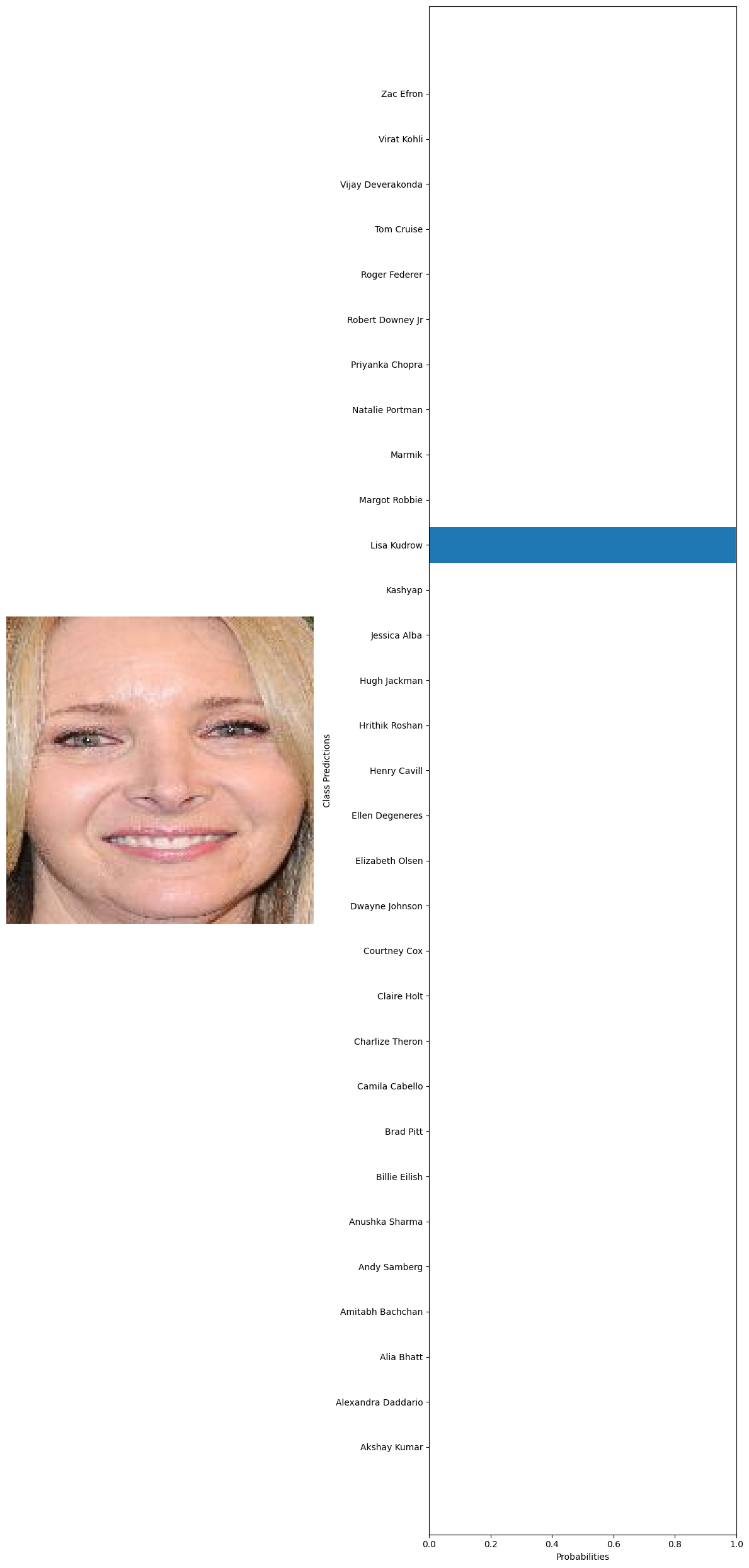
True label: Lisa Kudrow Predicted label: Lisa Kudrow
True label: Vijay Deverakonda Predicted label: Vijay Deverakonda
True label: Lisa Kudrow Predicted label: Lisa Kudrow
Accuracy: 0.9




Phone
(+91) 9645-095-759Address
Kallampali, Punnappala P.OWandoor, Malappuram Dist
Kerala, India